Add to this, the fact that the Web lacks the bibliographic control standards we take for granted in the print world: There is no equivalent to the ISBN to uniquely identify a document; no standard system, analogous to those developed by the Library of Congress, of cataloguing or classification; no central catalogue including the Web's holdings. In fact, many, if not most, Web documents lack even the name of the author and the date of publication. Imagine that you are searching for information in the world's largest library, where the books and journals (stripped of their covers and title pages) are shelved in no particular order, and without reference to a central catalogue. A researcher's nightmare? Without question. The World Wide Web defined? Not exactly. Instead of a central catalogue, the Web offers the choice of dozens of different search tools, each with its own database, command language, search capabilities, and method of displaying results.
Given the above, the need is clear to familiarize yourself with a variety of search tools and to develop effective search techniques, if you hope to take advantage of the resources offered by the Web without spending many fruitless hours flailing about, and eventually drowning, in a sea of irrelevant information.
Search engines allow the user to enter keywords that
are run against a database (most often created automatically, by "spiders" or
"robots"). Based on a combination of criteria (established by the user and/or
the search engine), the search engine retrieves WWW documents from its database
that match the keywords entered by the searcher. It is important to note that
when you are using a search engine you are not searching the Internet "live", as
it exists at this very moment. Rather, you are searching a fixed database that
has been compiled some time previous to your search.
While all search engines are intended to perform the same task, each goes
about this task in a different way, which leads to sometimes amazingly different
results. Factors that influence results include the size of the database, the
frequency of updating, and the search capabilities. Search engines also differ
in their search speed, the design of the search interface, the way in which they
display results, and the amount of help they offer.
In most cases, search engines are best used to locate a specific piece of
information, such as a known document, an image, or a computer program, rather
than a general subject.
Examples of search engines include:
The growth in the number of search engines has led to the creation of "meta"
search tools, often referred to as multi-threaded search engines. These
search engines allow the user to search multiple databases simultaneously, via a
single interface. While they do not offer the same level of control over the
search interface and search logic as do individual search engines, most of the
multi-threaded engines are very fast. Recently, the capabilities of meta-tools
have been improved to include such useful features as the ability to sort
results by site, by type of resource, or by domain, the ability to select which
search engines to include, and the ability to modify results. These
modifications have greatly increased the effectiveness and utility of the
meta-tools.
Popular multi-threaded search engines
include:
Subject-specific search engines do not attempt to index the entire
Web. Instead, they focus on searching for Web sites or pages within a defined
subject area, geographical area, or type of resource. Because these specialized
search engines aim for depth of coverage within a single area, rather than
breadth of coverage across subjects, they are often able to index documents that
are not included even in the largest search engine databases. For this reason,
they offer a useful starting point for certain searches. The table below lists
some of the subject-specific search engines by category. For a more
comprehensive list of subject-specific search engines, see one of the following
directories of search tools:
Table of selected
subject-specific search engines
Regional (Canada)
|
Companies |
| People (E-mail addresses) | People (Postal addresses & telephone numbers) |
| Images | Jobs |
| Games | Software |
| Health/Medicine | Education/Children's Sites |
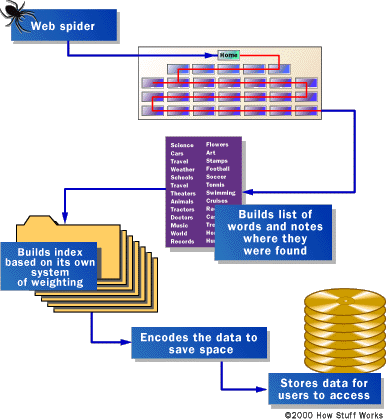
How Search Engines Work.
Before a search engine can tell you
where a file or document is, it must be found. To find information on the
hundreds of millions of Web pages that exist, a search engine employs special
software robots, called spiders, to build lists of the words found on Web sites.
When a spider is building its lists, the process is called Web crawling. (There
are some disadvantages to calling part of the Internet the World Wide Web -- a
large set of arachnid-centric names for tools is one of them.) In order to build
and maintain a useful list of words, a search engine's spiders have to look at a
lot of pages.
Google.com began as an academic search engine. In the paper that describes how the system was built, Sergey Brin and Lawrence Page give an example of how quickly their spiders can work. They built their initial system to use multiple spiders, usually three at one time. Each spider could keep about 300 connections to Web pages open at a time. At its peak performance, using four spiders, their system could crawl over 100 pages per second, generating around 600 kilobytes of data each second.
Keeping everything running quickly meant building a system to feed necessary information to the spiders. The early Google system had a server dedicated to providing URLs to the spiders. Rather than depending on an Internet service provider for the Domain Name Server (DNS) that translates a server's name into an address, Google had its own DNS, in order to keep delays to a minimum.
When the Google spider looked at an HTML page, it took note of two things:
These different approaches usually attempt to make the spider operate faster, allow users to search more efficiently, or both. For example, some spiders will keep track of the words in the title, sub-headings and links, along with the 100 most frequently used words on the page and each word in the first 20 lines of text. Lycos is said to use this approach to spidering the Web.
Other systems, such as AltaVista, go in the other direction, indexing every single word on a page, including "a," "an," "the" and other "insignificant" words. The push to completeness in this approach is matched by other systems in the attention given to the unseen portion of the Web page, the meta tags.
Once the spiders have completed the task of finding information on Web pages (and we should note that this is a task that is never actually completed -- the constantly changing nature of the Web means that the spiders are always crawling), the search engine must store the information in a way that makes it useful. There are two key components involved in making the gathered data accessible to users: the information stored with the data, and the method by which the information is indexed.
In the simplest case, a search engine could just store the word and the URL where it was found. In reality, this would make for an engine of limited use, since there would be no way of telling whether the word was used in an important or a trivial way on the page, whether the word was used once or many times or whether the page contained links to other pages containing the word. In other words, there would be no way of building the "ranking" list that tries to present the most useful pages at the top of the list of search results.
To make for more useful results, most search engines store more than just the word and URL. An engine might store the number of times that the word appears on a page. The engine might assign a "weight" to each entry, with increasing values assigned to words as they appear near the top of the document, in sub-headings, in links, in the meta tags or in the title of the page. Each commercial search engine has a different formula for assigning weight to the words in its index. This is one of the reasons that a search for the same word on different search engines will produce different lists, with the pages presented in different orders.
Regardless of the precise combination of additional pieces of information stored by a search engine, the data will be encoded to save storage space. For example, the original Google paper describes using 2 bytes, of 8 bits each, to store information on weighting -- whether the word was capitalized, its font size, position, and other information to help in ranking the hit. Each factor might take up 2 or 3 bits within the 2-byte grouping (8 bits = 1 byte). As a result, a great deal of information can be stored in a very compact form. After the information is compacted, it's ready for indexing.
An index has a single purpose: It allows information to be found as quickly as possible. There are quite a few ways for an index to be built, but one of the most effective ways is to build a hash table. In hashing, a formula is applied to attach a numerical value to each word. The formula is designed to evenly distribute the entries across a predetermined number of divisions. This numerical distribution is different from the distribution of words across the alphabet, and that is the key to a hash table's effectiveness.
In English, there are some letters that begin many words, while others begin
fewer. You'll find, for example, that the "M" section of the dictionary is much
thicker than the "X" section. This inequity means that finding a word beginning
with a very "popular" letter could take much longer than finding a word that
begins with a less popular one. Hashing evens out the difference, and reduces
the average time it takes to find an entry. It also separates the index from the
actual entry. The hash table contains the hashed number along with a pointer to
the actual data, which can be sorted in whichever way allows it to be stored
most efficiently. The combination of efficient indexing and effective storage
makes it possible to get results quickly, even when the user creates a
complicated search.
Subject Directories/Portals.
Subject
directories, or portals, are hierarchically organized indexes of
subject categories that allow the Web searcher to browse through lists of Web
sites by subject in search of relevant information. They are compiled and
maintained by humans and many include a search engine for searching their own
database.
Subject directory databases tend to be smaller than those of the search engines, which means that result lists tend to be smaller as well. However, there are other differences between search engines and subject directories that can lead to the latter producing more relevant results. For example, while a search engine typically indexes every page of a given Web site, a subject directory is more likely to provide a link only to the site's home page. Furthermore, because their maintenance includes human intervention, subject directories greatly reduce the probability of retrieving results out of context.
Because subject directories are arranged by category and because they usually return links to the top level of a web site rather than to individual pages, they lend themselves best to searching for information about a general subject, rather than for a specific piece of information.
Examples of subject directories include:
Specialized subject directories
Due to the
Web's immense size and constant transformation, keeping up with important sites
in all subject areas is humanly impossible. Therefore, a guide compiled by a
subject specialist to important resources in his or her area of expertise is
more likely than a general subject directory to produce relevant information and
is usually more comprehensive than a general guide. Such guides exist for
virtually every topic. For example, Voice of the
Shuttle (http://vos.ucsb.edu) provides an excellent starting point for
humanities research. Film buffs should consider starting their search with the
Internet Movie Database (http://us.imdb.com).
Just as multi-threaded search engines attempt to provide simultaneous access to a number of different search engines, some web sites act as collections or clearinghouses of specialized subject directories. Many of these sites offer reviews and annotations of the subject directories included and most work on the principle of allowing subject experts to maintain the individual subject directories. Some clearinghouses maintain the specialized guides on their own web site while others link to guides located at various remote sites.
Examples of clearinghouses include:
Search logic refers to the way in which you, and the search engine you are using, combine your search terms. For example, the search Okanagan University College could be interpreted as a search for any of the three search terms, all of the search terms, or the exact phrase. Depending on the logic applied, the results of each of the three searches would differ greatly. All search engines have some default method of combining terms, but their documentation does not always make it easy to ascertain which method is in use. Reading online Help and experimenting with different combinations of words can both help in this regard. Most search engines also allow the searcher to modify the default search logic, either with the use of pull-down menus or special operators, such as the + sign to require that a search term be present and the - sign to exclude a term from a search.
Boolean logic is the term used to describe certain logical operations that are used to combine search terms in many databases. The basic Boolean operators are represented by the words AND, OR and NOT. Variations on these operators, sometimes called proximity operators, that are supported by some search engines include ADJACENT, NEAR and FOLLOWED BY. Whether or not a search engine supports Boolean logic, and the way in which it implements it, is another important consideration when selecting a search tool. The following diagrams illustrate the basic Boolean operations.
AND  |
OR  |
NOT  |
Boolean operators are most useful for complex searches, while the + and - operators are often adequate for simple searches.
| Ctrl-F: After following a link to a document retrieved with a search engine, it is sometimes not immediately apparent why the document has been retrieved. This may be because the words for which you searched appear near the bottom of the document. A quick method of finding the relevant words is to type Ctrl-F to search for the text in the current document. |
| Bookmark your results: If you are likely to want to repeat a search at a later date, add a bookmark (or favorite) to your current search results. |
| Right truncation of URLs: Often, a search will retrieve links to many documents at one site. For example, searching for "Okanagan University College Library" will retrieve not only the OUC Library home page (http://www.ouc.bc.ca/libr), but also any pages that contain the phrase "Okanagan University College Library", whether or not they are linked to the home page (eg. this page - http://www.ouc.bc.ca/libr/connect96/search.htm). Rather than clicking on each URL in succession to find the desired document, truncate the URL at the point at which it appears most likely to represent the document you are seeking and type this URL in the Location box of your web browser. |
| Guessing URLs: Basic knowledge of the way in which URLs are constructed will help you to guess the correct URL for a given web site. For example, most large American companies will have registered a domain name in the format www.company_name.com (eg. Microsoft - www.microsoft.com); American universities are almost always in the .edu domain (eg. Cornell - www.cornell.edu or UCLA - www.ucla.edu); and Canadian universities follow the format www.university_name.ca (eg. Simon Fraser University - www.sfu.ca or the University of Toronto - www.utoronto.ca). |
| Wildcards: Some search engines allow the use of "wildcard" characters in search statements. Wildcards are useful for retrieving variant spellings (eg. color, colour) and words with a common root (eg. psychology, psychological, psychologist, psychologists, etc.). Wildcard characters vary from one search engine to another, the most common ones being *, #, and ?. Some search engines permit only right truncation (eg. psycholog*), while others also support middle truncation (eg. colo*r). |
| Relevance ranking: All of the search engines covered in this workshop use an algorithm to rank retrieved documents in order of decreasing relevance. (3) Consequently, it is often not necessary to browse through more than the first few pages of results, even when the total results number in the thousands. Furthermore, some search engines (eg. AltaVista) allow the searcher to determine which terms are the most "important", while others have a "more like this" feature that permits the searcher to generate new queries based on relevant documents retrieved by the initial search. These features are discussed in more detail in the following section of this document. |